MVCC
InnoDB存储引擎的并发是通过MVCC(Multi-Version Concurrency Control)实现的. 与MVCC相对的是LBCC(Lock-Based Concurrency Control), 对比来说好处在于 读写不互斥.
在读多写少的应用中,读写不冲突是很重要的,可大幅度增加系统的并发性能. 这也是为什么现阶段大部分关系型数据库都是支持MVCC的.
Snapshot Read & Current Read
在MVCC并发控制中,读操作可以分成两类: 快照读(snapshot read)与当前读(current read).快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁.
当前读,读取的是记录的最新版本. 并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录.
| 快照读 | 当前读 |
|---|---|
| select * from table where ?; | select * from table where ? lock in share mode; |
| select * from table where ? for update; | |
| insert into table values (…); | |
| update table set ? where ?; | |
| delete from table where ?; |
当前读,读取的是记录的最新版本. 并且,在读取之后还需要保证其他并发事务不能修改当前记录,对当前记录加锁. 除 in share mode 关键字加的是共享锁(S锁)外,
其他语句均加的是排它锁(X锁).
DML执行过程
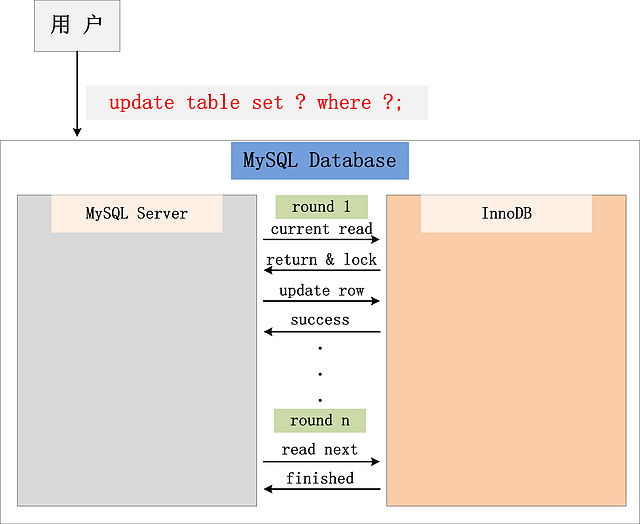
- Server层在拿到更新语句后, 先开启一个事务(申请一个事务ID).
- Server层根据更新语句先查询出待修改的数据;
- Engine层根据条件查出数据后返回给Server层, 并将返回的数据加锁;
- Server层拿到数据后, 执行逻辑后. 将修改后的数据再次交由Engine层;
- Engine将数据追加到内存缓存池中(后续会再放到undoLog中), 并返回Server层成功;
- Server层接收到修改成功后, 会通过 read next 指令 读取流中的下一批数据重复处理;
- 处理完成后, Server层会向Engine层发送事务提交指令. 更新完成;
Two-Phase Locking
大部分的关系型数据库加锁的一个原则就是二阶段锁. 二阶段锁相对比较容易理解, 说的是锁的操作分为两个阶段: 加锁阶段和解锁阶段. 并保证加锁阶段与解锁阶段
彼此不相交.
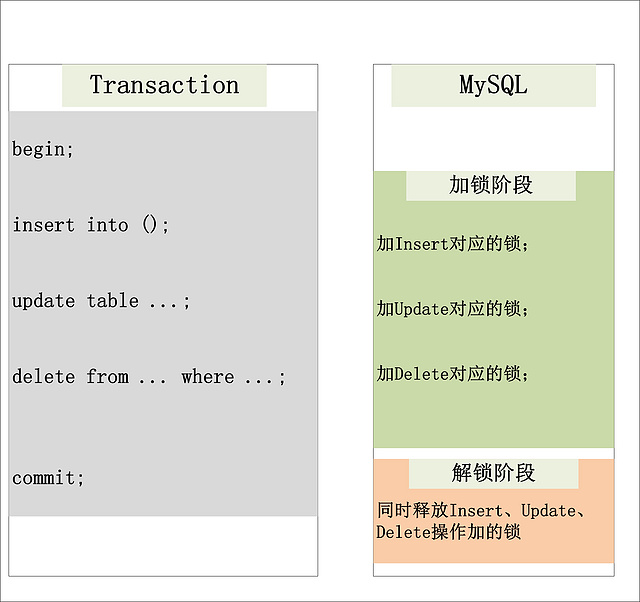
2PL就是将加锁/解锁分为两个完全不相交的阶段. 加锁阶段: 只加锁,不放锁. 解锁阶段: 只放锁,不加锁.
事务隔离级别(Isolation Level)
事务隔离级别
IL简单的讲可以理解为在当前读情况下,事务隔离级别分为四种. 是 "数据库系统" 中的一个概念, 并不局限于InnoDB. 几乎所有的关系型数据库中都会有这个概念. 只是,可能并不四种全部支持.
在MySQL的事务引擎中,InnoDB是使用最广泛的一种. 它默认的事务隔离级别为RR(重复读).在标准的RR模式下是无法避免幻读问题的,但InnoDB使用了Next-Key Lock(行锁加间歇锁)避免了幻读问题.
Read UnCommitted
可以读取到未提交的记录,几乎不会使用.因为无法保证事务的隔离性.
Read Committed
通过对读取到的记录加锁实现.所以可以解决脏读问题,但依旧会出现幻读的情况.
Repeatable Read
通过对读取到的记录加锁实现,并在满足查询条件的区间加间歇锁.所以不会出现幻读情况.
Serializable
将并发控制降低到悲观锁级别,快照读会退化成当前读.不会出现问题,但并发效率会降低.
SQL语句的加锁过程分析
针对与读操作.除在事务隔离级别为Serializable模式下,才会对符合条件的数据(和数据区间)进行加锁.其他情况下是不会对数据进行加锁的.
针对与写操作.在不同事务隔离级别下, 查询条件是否主键, 查询条件是否二级索引, 查询条件是否唯一索引和SQL的执行计划都有着很大的关系.
以 delete from table where id = 1 为例;
- RC模式下. 当ID为主键时, 此时只需要在聚簇索引上对应行上加行锁即可实现;
- RC模式下. 当ID非主键但其上有唯一索引时, InnoDB会加两把锁.第一把是在非唯一索引上对满足条件的行加锁.并通过其对应的主键对聚簇索引中的行加锁;为什么会在聚簇索引上加锁呢?因为为了避免其他事务在此时更新ID列;
- RC模式下. 当ID列非主键也无唯一索引时, InnoDB会对全部表中的记录加锁.
MySQL 层级
MySQL是分为两层的Server层和Engine层. Server层负责SQL的解析优化,Engine层负责数据的存取.
当数据无法通过索引进行精准匹配时,Engine层就会把符合条件的数据全部返回. 由Server层对数据进行再次过滤.
只要是在当前读状态下,Engine层返回给Server层的数据都是会加锁的.
但是, 为了效率考量.MySQL对这部分还是做了优化的. 即当Server层过滤后发现多余的数据不需要加锁后,会立即通知Engine层将锁释放,而不是在事务提交时再释放. 显然这是一个反范式优化.违反了2PL的语义.
- RR模式下, 当ID列非主键但存在非唯一索引时, InnoDB会加三把锁. 第一把是在非唯一索引对应记录上的行锁, 第二把是在非唯一索引对应记录的前后加入间歇锁, 第三把是在聚簇索引对应主键上加行锁.
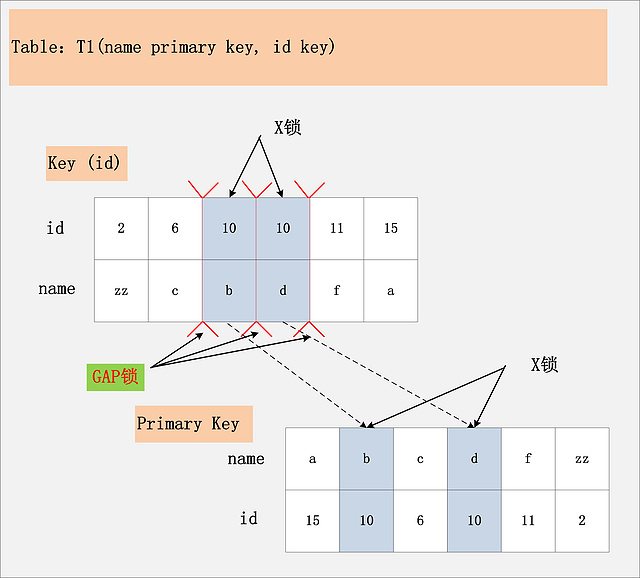
- RR模式下, 当ID非主键也无唯一索引时. InnoDB会对全表的数据记录加锁.并在此基础上对所有记录间加入间隙锁. 本质上已经是表锁了.
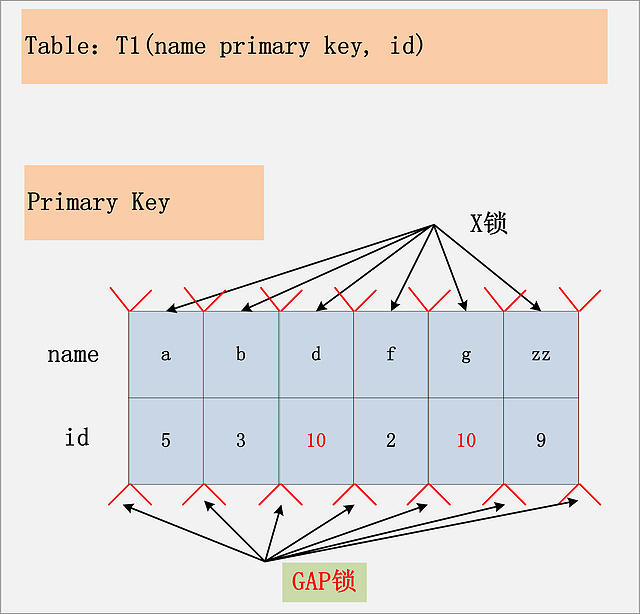
示例:
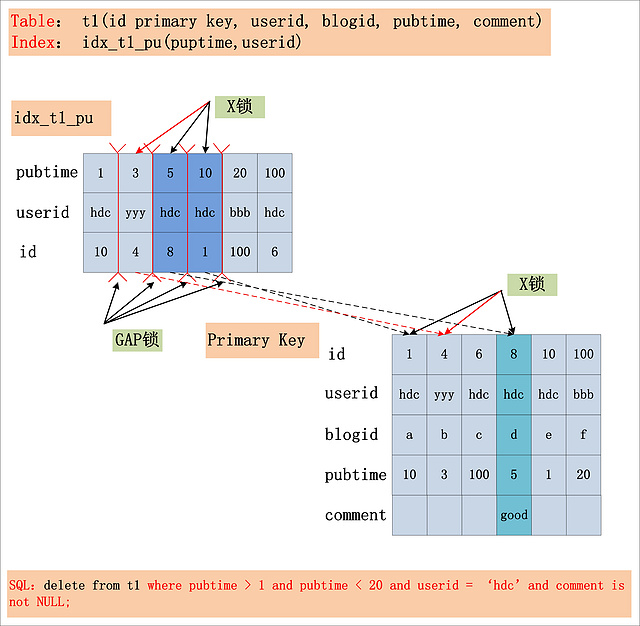
IndexKey: 用于查询在索引中的连续范围.
IndexFilter: 在使用IndexKey确定了查询的连续范围后, 需要使用其他where条件来进行过滤.
TableFilter: where条件中不能通过索引处理的查询条件.
从上图中可以看出. 在默认的RR模式下, 由IndexKey确定的连续范围将会加上间歇锁. IndexFilter指定的过滤条件将会被加上行锁. IndexFilter在5.6版本前不支持索引下推(ICP),多出来的数据也会被加上行锁
返回给Server层进行处理.这时,二级索引上还会加上红箭头指示的行锁.
总结:
- 只有在RR模式下, 才会启用间隙锁或NK锁;
- 除串行化模式下, 所有DQL语句走的都是快照读.即对数据不加锁;
- Engine层无法通过索引精准匹配的数据, 会由Server层再次过滤.但会全部加锁;
- 通过二级索引匹配到的数据会先在二级索引上加锁, 最后通过二级索引对聚簇索引加锁;
死锁原理与分析
死锁的发生与否和执行了多少SQL并没有一点关系, 死锁的关键在于, 两个以上的session对同一批共享数据的加锁顺序不一致导致的. 只有了解InnoDB的加锁机制,并根据各自加锁的顺序分析才能找到照成死锁的最终原因.